AI Systems Don't Fail Because of the Model
They fail because of the systems around them.
Most teams are not using AI wrong because they chose the wrong model.
They are using AI wrong because they have not built the right environment around it.
There is a reason some teams are shipping meaningful work with a handful of engineers while others cannot get a consistent refactor through an agent pipeline. The difference is rarely GPT-5 versus Claude Opus. It is not temperature, token limits, or prompt phrasing. Those things matter, but far less than people want them to.
The difference is the harness.
The difference is not the model. It is the environment.
That word gets used loosely, so it is worth being precise about what it means. A harness is not a system prompt. It is not a wrapper around an API call. It is not a chatbot with memory, an eval dashboard, or a pile of prompt templates.
A harness is the designed environment in which a model operates. It includes the tools it can call, the shape of the information it receives, how its working history is compressed and managed, how errors are caught before they cascade, and how work is handed off across time without losing coherence.
Once you look at the serious work in this space, the pattern becomes hard to ignore. Whether you study the Princeton SWE-agent paper, Anthropic’s work on long-running coding agents, or OpenAI’s experience shipping large systems through Codex, the lesson keeps repeating:
The model matters. The harness matters more.
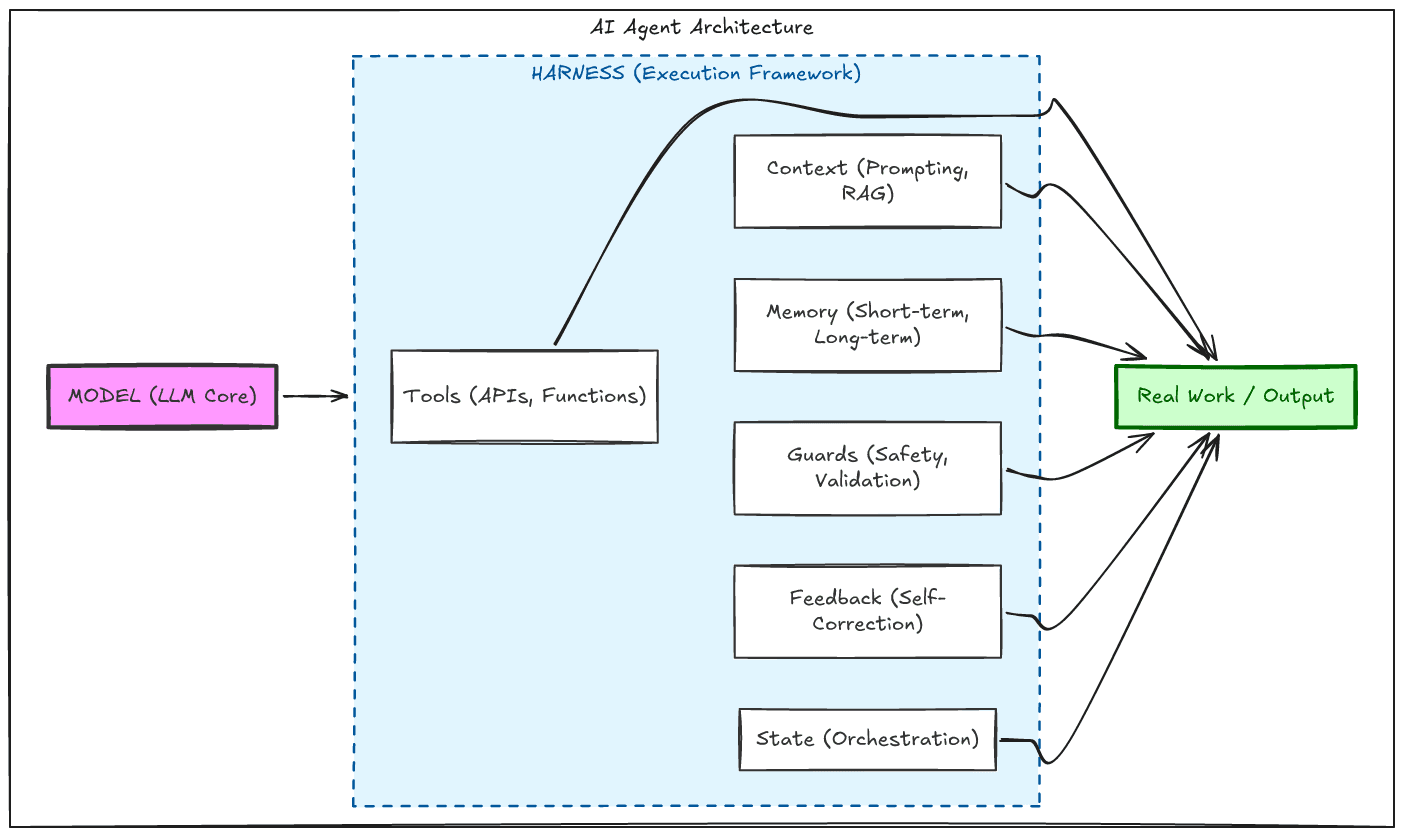
The model is only one layer. The environment around it determines what it can reliably do.
The mistake everyone is making
The industry has spent an enormous amount of time arguing about models, prompts, and benchmarks while underinvesting in the thing that determines whether any of those capabilities become reliable.
Raw capability is not the same as usable capability.
A developer with a modern IDE, debugger, version control, and CI pipeline is dramatically more effective than the same developer dropped into a bare terminal with no structure around the task. The tools do not make the developer smarter. They reduce friction, manage state, surface the right information at the right time, and catch mistakes before they compound.
Language models are no different.
They do not operate from a stable internal understanding of the world. They operate over tokens in context. What they can do in a given moment is shaped by what is present, how it is structured, and how much noise competes with the signal.
That means the interface is not a convenience layer.
For an agent, the interface is part of cognition.
This is why the same model can look brilliant in one environment and brittle in another. The intelligence did not change. The surrounding system did.
What a harness actually is
A good harness does five things well.
- First, it constrains what the model sees so that context remains useful rather than polluted.
- Second, it gives the model tools that match the task instead of forcing it to improvise through raw shells and oversized outputs.
- Third, it closes feedback loops early, catching mistakes at the moment they are introduced.
- Fourth, it preserves continuity across time, so work can span sessions without collapsing into confusion.
- Fifth, it enforces structure mechanically, so correctness does not depend on the model remembering every rule on every turn.
This is true whether the task is coding, research, operations, or long-running multi-step execution. The details change. The underlying problem does not.
Without a harness, a model is left to reason in an environment that is too noisy, too fragile, and too understructured to produce reliable work.
With one, the model becomes something else entirely: not just a generator of outputs, but a participant in a system that can improve over time.
Why context is not memory
One of the most damaging mistakes in AI engineering is treating the context window like RAM.
It is not.
A context window is closer to the model’s working consciousness for a single moment. Every token competes for attention. Every irrelevant detail consumes capacity. Every oversized output degrades what comes next.
This is why so many agent systems fail in such predictable ways. They let the model dump thousands of lines of search results into its own working state. They expose raw interfaces that return far more than the task requires. They confuse more information with better reasoning.
But reasoning does not improve when the environment becomes noisy. It deteriorates.
The teams that have gotten real performance gains out of agents have learned this quickly. They cap output. They force search refinement. They structure file views. They compress history. They preserve only what matters.
That is not prompt engineering.
That is systems design.
What serious teams discovered
The Princeton SWE-agent work made this point clearly: the interface between model and computer environment can change results dramatically even when the underlying model stays exactly the same.
That should have reset the conversation.
Not because benchmarks are everything, but because the implication is so important: environment design can create the difference between a tool that works and one that thrashes.
Anthropic ran into the same lesson from another direction. Once tasks became too large to fit in a single context window, the core challenge stopped being code generation and became continuity. How do you preserve orientation across sessions? How do you prevent partially completed work from collapsing into ambiguity? How do you stop future agent runs from wasting half their budget rediscovering state?
The answer was not to buy a bigger model.
It was scaffolding: progress files, feature lists, startup routines, clean-state requirements, persistent structure.
OpenAI’s internal Codex work arrived at a similar conclusion at a larger scale. Once agents could generate huge amounts of code, the bottleneck shifted. The job was no longer writing code directly. It was building the environment that made agent output reviewable, verifiable, constrained, and useful.
Different teams. Different contexts. Same lesson.
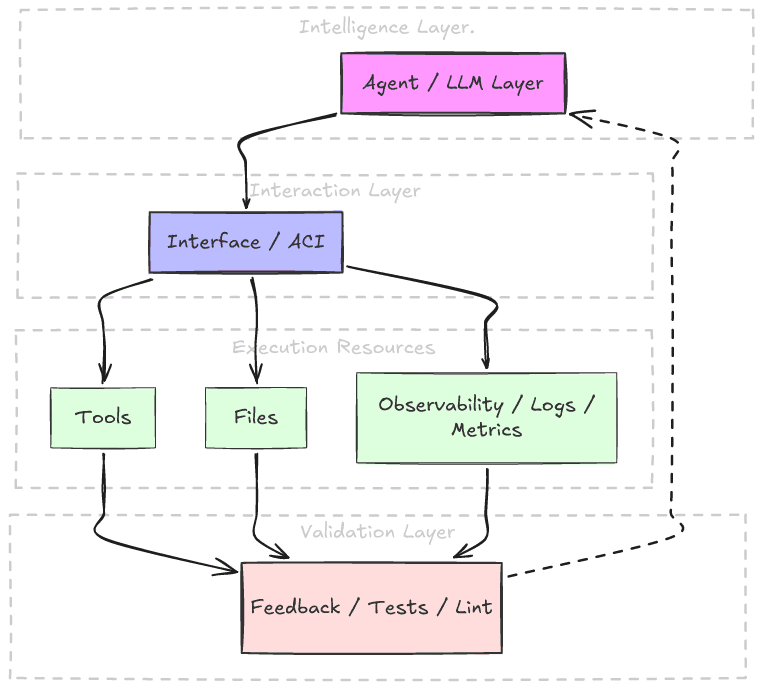
Across different teams and implementations, the pattern repeats: structure, feedback, memory, and constrained interfaces outperform raw interaction.
The model is not the whole system.
Treating it like it is will produce unreliable results every time.
The patterns that repeat
These patterns are not optional. They are what make systems durable.
Across all of these efforts, a handful of design patterns keep showing up.
Progressive disclosure
Do not show the model everything at once. Give it the smallest useful view, then let it navigate deeper as needed.
Structured state
Use progress files, feature lists, plans, and machine-readable artifacts to preserve continuity across sessions.
Mechanical enforcement
Architectural rules, validation, and quality constraints should be enforced by tools, not remembered ad hoc.
Integrated feedback loops
Catch syntax problems, runtime failures, user-flow issues, and state drift as early as possible.
Repository-visible truth
If the agent cannot find the information in the environment it operates in, that information effectively does not exist.
These are not coding-agent tricks. They are general rules for making AI systems durable.

Durable AI systems depend on feedback loops: constrained inputs, observable execution, structured state, and corrective signals over time.
What this means for engineers
The most valuable skill in applied AI is not clever prompting.
It is environment design.
It is knowing how to shape context, how to reduce cognitive noise, how to preserve state across time, how to build feedback loops that catch error early, and how to structure systems so that intelligence does not float free of process.
That is why so much of the current AI discourse feels shallow. It is focused on outputs instead of environments. It confuses flashes of capability with reliable systems.
But reliable systems are what matter.
The engineers who will matter most in this next phase are not the ones who can make a model look impressive in a demo. They are the ones who can build the scaffolding that makes a model usable in real work.
That requires a different mindset.
Not: how do I get the model to do this?
But: what does the environment need to provide so this can happen reliably?
That shift is the real work.
You are not debugging the model. You are debugging the environment.
The model is the reasoning engine. The environment determines what it can actually do.
Build accordingly
There is a pattern in how foundational technologies mature. In the beginning, most of the attention goes to raw capability. Later, value accumulates around the systems that make that capability navigable, reliable, and operational.
AI is following the same path.
The capability is here. The question now is who will build the environments that make it useful.
Not wrappers.
Not demos.
Not prompt theater.
Harnesses.
The model is the reasoning engine. The harness is what gives that reasoning structure, memory, constraints, and feedback.
That is where applied AI becomes real.
Build accordingly.
I work with teams building complex systems under real-world constraints.